
OCR(光学式文字認識)による画像からのテキスト検出・抽出するサービス(API)である、Google の Cloud Vision API の出力書式や設定手順を説明します(サンプルプログラムはこちら)。
限度内であれば、無料で利用できる API サービスです。
参考: 画像からテキストを検出する OCR サービス - Microsoft Computer Vision
参考: Google と Microsoft の OCR API の PHP プログラムサンプル
Vision API とは
GCP【Google Cloud Platform】が提供する API サービスで、画像をアップロードすることで画像内にあるテキストを検出して JSON データとして返してくれる OCR サービスです。
手書き文字の検出も可能です。
テキスト検出にはすでにレーニング済みの機械学習モデルが使用されるため、学習モデルを独自にカスタムして構築したい場合は、AutoML Vision というサービスを利用してください。
GCP のプロダクトは名称がとっ散らかっていて非常にわかりにくいですが、概ね以下のような構成になっているかと思います。
Google Cloud Platform
│
└ Vision AI プロダクト
│
├ AutoML Vision(Cloud AutoML:カスタム学習モデル)
│
└ Vision API(Cloud Vision:学習済モデル)
│
├ 光学式文字認識(OCR)
├ 顔検出
├ ランドマーク検出
├ ロゴ検出
・
・
・
Vision API ではテキスト検出の他にも、顔検出やランドマーク検出などもできます。
無料枠の使用量上限
毎月 1,000 ユニット( ≒ API 呼び出し回数)までは無料になります。
以降、1,001 ~ 5,000,000 ユニット/月までは 1000 ユニット当り $1.50、5,000,001 以上のユニット/月は 1000 ユニット当り $0.6 になります。
※金額は変更になる場合がありますので、必ず GCP のサイトにてご確認ください。
※私は AutoML Vision の価格改定で痛い目に合いそうになりました。
参考: Vision API 料金
参考: Google Cloud AutoML Vision で新たな課金
Vision API の設定
Vision API を利用するには、Google のアカウントと API のセットアップが必要です。
まずは Google アカウントを作成後、Cloud Console にログインします。
Google Cloud Console
https://console.cloud.google.com/
以降の手順はここでも解説いたしますが、詳細は公式の解説の方をご確認ください。
参考: クイックスタート: Vision API を設定する
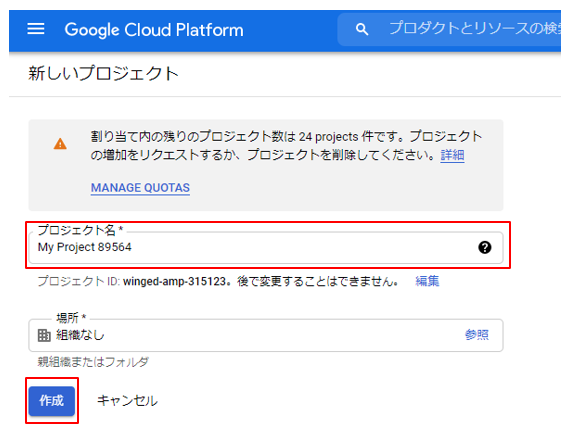
プロジェクトを作成する
プロジェクトとは、Google Cloud サービスを利用する基本的な単位で、ここで利用するサービスや利用するメンバーの権限、課金情報との紐づけなどを行うことができます。
初めて Cloud Console を利用する方は、プロジェクト選択画面に飛ばされますので、そこでプロジェクトを作成してください。
必要なものは任意のプロジェクト名だけです。
「組織」や「フォルダ」を利用してプロジェクトを階層管理している場合は、それらを選択します。
参考: リソース階層

すでに Cloud Console ご利用の方はダッシュボード画面からプロジェクトを選択するか、左メニューの「IAM と管理」→「リソースの管理」からプロジェクトを作成します。
参考: プロジェクトの作成と管理

課金を有効にする
請求先アカウントを作成しプロジェクトに紐づけます。
無料枠を利用するだけでも有効な請求先アカウントの設定が必要になります。
左メニューの「お支払い」を選択すると課金情報の画面が表示されます。
アカウントを新規に作成する場合は、「アカウント作成」をクリックします。
すでに作成されたアカウントにプロジェクトを紐づけたい場合は、「マイプロジェクト」より紐づけてください。

詳しくは公式の以下のページを参照してください。
参考: Cloud 請求先アカウントの作成、変更、閉鎖
API を有効にする
左メニューの「API とサービス」→「ライブラリ」から API ライブラリ一覧画面を表示します。
少し下の「Cloud Vision API」を選択し、遷移した画面で「有効にする」をクリックします。
参考: サービスの有効化と無効化

認証を設定する
左メニューの「認証情報」より認証情報画面を表示します。
画面上部にある「認証情報を作成」より「API キー」を選択します。
参考: 認証の概要
参考: API キーの使用


左画面中段に「API キー 1」などの仮の名前のついた API キーが表示されます。
なんの制限もつけれられていないキーには▲マークがつけられ、警告メッセージが表示されます。
右側の鉛筆アイコンをクリックして「API キーの制限と名前変更」の画面へ移動します。

移動先の画面よりデフォルトでつけられた名前をわかりやすいものに変更します。
また、API の呼び出しをサーバから行う場合は、IP アドレスによるアクセス制限を設定しておくと良いでしょう。
「項目を追加」をクリックするとフォームが表示されますので、IP アドレスを入力します。

「API の制限」では、このキーで呼び出し可能な API を制限できます。
例えばこのキーを Vision API でのみ使用可能にしたい場合は「キーを制限」を選択し、「Cloud Vision API」を選択して OK をクリックします。
最後に画面最下部にある「保存」ボタンをクリックして設定の完了です。
")
ここで作成された API キーは API を呼び出すプログラムで必要となりますので、あらかじめどこかにメモっておいてください。
これでようやく API を利用できるようになりました。
リクエストの形式
JSON 形式でリクエストデータを生成し、指定の URL に POST します。
●HTTP メソッドと URL
POST https://vision.googleapis.com/v1/images:annotate
{
"requests": [{
"features": [{
"type": "DOCUMENT_TEXT_DETECTION",
"maxResults": 10
}],
"image": {
"content": "/9j/4QAYRXhpZgAA..." // base64形式の画像データ
//"source": {
// "imageUri": "https://example.com/img/test.jpg"
// "gcsImageUri": "gs://cloud-samples-data/img/test.jpg"
//}
},
"imageContext": {
"languageHints": ["ja"]
}
}]
}●フィールド値の説明
features
画像に対して行うアノテーションのタイプを指定します。
features.type
指定できるタイプは以下の2種類があります。
・DOCUMENT_TEXT_DETECTION
文字数の多い画像(文章や Web ページのキャプチャなど)に適しています。
高密度のテキストやドキュメントに応じてレスポンスが最適化され、ページ、ブロック、段落、単語、改行の情報が JSON に含まれます。
・TEXT_DETECTION
画像の中から単語や単語列のブロックを検出します。
たとえば、写真に道路名や交通標識が写っていれば、抽出された文字列全体、個々の単語、それらの境界ボックスが JSON レスポンスに含まれます。
features.maxResults(省略可)
返される結果の上限値を指定します。
features.model(省略可)builtin/latestを設定することで、最新バージョンの学習モデルを利用できます。
image
テキスト検出する画像を指定します。
指定方法は以下の3種類があります。
・image.content
base64 形式でエンコードされた画像ファイルのデータを設定します。
・image.source.imageUri
画像ファイルにアクセスできる公開された URL を設定します。
・image.source.gcsImageUri
Cloud Storage にある画像ファイルの場所を設定します。
imageContext(省略可)
境界ボックス、言語、クロップヒント、アスペクト比など、アノテーションを補足するヒントを指定します。
・imageContext.languageHints
言語を設定します。
手書き文字の検出の際に指定しておくと正解率が上がるかもしれません(ほとんどの場合指定不要のようです)。
参考: 画像内のテキストを検出する
参考: 画像内の手書き入力を検出する
参考: クイックスタート: コマンドラインの使用
レスポンスの形式
レスポンスデータはtextAnnotationsとfullTextAnnotationの2つで構成されます。
{
"responses":[
{
"textAnnotations": [
/* 画像解析結果 */
],
"fullTextAnnotation": {
/* 画像解析結果 */
}
}
]}textAnnotationsでは、検出された単語とその四隅の座標(単位:ピクセル)が配列で返されます。
1番目の配列には画像全体についての情報が入り、それ以降についてはそれぞれの単語ごとの情報が入ります。
四隅の座標は x, y で表され、左上、右上、右下、左下の順番で格納されます。
"textAnnotations": [
{ // 1番目の配列には画像全体に含まれる検出文字とその座標および言語
"boundingPoly": {
"vertices": [{"x":13,"y":10}, {"x":460,"y":10}, {"x":460,"y":477}, {"x":13,"y":477}]
},
"description": "検出されたすべての文字列",
"locale": "ja"
},{ // 2番目以降の配列には単語ごとの文字列とその座標
"boundingPoly": {
"vertices": [{"x":17,"y":14}, {"x":34,"y":14}, {"x":34,"y":35}, {"x":17,"y":35}]
},
"description": "検出された単語"
},
{}, {}, ・・・
]fullTextAnnotationsでは結果が、
ページ → ブロック → 段落 → 語 → 記号
のような階層構造で返されます。
「ページ」ではwidthとheight(単位:ピクセル)が取得でき、その他の階層ではそれぞれでboundingBox.verticesにて四隅の座標(単位:ピクセル)を取得できます。
四隅の座標は x, y で表され、左上、右上、右下、左下の順番で格納されます。
検出した実際のテキストは「記号」の階層まで読み込まないと取得できないため、そのままでは使い勝手が悪いと思う場合は自身のプログラムで加工した方が良いでしょう。
"fullTextAnnotation": {
"text": "検出されたすべての文字列",
"pages": [{
"width": 457,
"height": 457,
"blocks": [{
"blockType": "TEXT",
"boundingBox": {
"vertices": [{"x":17,"y":14}, {"x":34,"y":14}, {"x":34,"y":35}, {"x":17,"y":35}]
},
"paragraphs": [{
"boundingBox": {
"vertices": [{"x":17,"y":14}, ・・・]
},
"words": [{
"boundingBox": {
"vertices": [{"x":17,"y":14}, ・・・]
},
"symbols": [{
"boundingBox": {
"vertices": [{"x":17,"y":14}, ・・・]
},
"text": "あ"
},
{/* symbol */}, {/* symbol */}・・・]
},
{/* word */}, {/* word */}・・・]
},
{/* paragraph */}, {/* paragraph */}・・・]
},
{/* block */}, {/* block */}・・・]
},
{/* page */}, {/* page */}・・・]
}・ページ【pages】
おおよそ画像全体を表します。
このページに含まれるブロック情報、およびこのページの縦横幅やその他のメタ情報(検出言語や結果の信頼性など)が入ります。
・ブロック【blocks】
テキストの集まりを矩形に区切った領域を表します。
このブロックに含まれる段落情報、およびこのブロックの四隅の座標やその他のメタ情報が入ります。
現状、blockTypeは TEXT だけのようなので判定しなくて良いかもしれません。
・段落【paragraphs】
複数の単語の集まりを改行などの区切り文字で区切った領域を表します。
この段落に含まれる語情報、およびこの段落の四隅の座標やその他のメタ情報が入ります。
・語【words】
1つの単語です。
この語に含まれる記号情報、およびこの語の四隅の座標やその他のメタ情報が入ります。
・記号【symbols】
1つの文字あるいは句読点などの記号です。
この記号のテキストデータと四隅の座標、その他のメタ情報が入ります。
参考: ドキュメント テキストのチュートリアル
参考: 画像内のテキストを検出する(「イベントに」をクリック)
参考: 画像内の手書き入力を検出する(「イベントに」をクリック)
fullTextAnotation は領域を四辺形に切り取るか?
ブロックなどの領域は、頂点座標の配列であるboundingBoxで示されます。
ブロックが必ず矩形であるならば、必要な座標は左上と右下(もしくは右上と左下)だけであるため、boundingBoxとなっているのは四辺形となる領域の切り取りが可能なためではないかとの予想をして色々試してみましたが、実際には矩形での切り取りしか行わないようでした(厳密には座標の±1の違いにより四辺形になる場合があります)。
したがって自身のプログラム上で座標データを保持する場合は、左上と右下の2つの座標に最適化した方がデータの扱いが楽になるかもしれません。

コメント
こんにちは
追加料金がかかるのは1ユニットあたりではなく1000ユニットあたりだと思いますよ
ご指摘ありがとうございます。