
OCR(光学式文字認識)による画像からのテキスト検出・抽出するサービス(API)である、Microsoft の Computer Vision の出力書式や設定手順を説明します (サンプルプログラムはこちら) 。
12 ヵ月の間は、5000 件まで無料で利用できる API サービスです。
参考: 画像からテキストを検出する OCR サービス - Google Cloud Vision API
参考: Google と Microsoft の OCR API の PHP プログラムサンプル
Computer Vision とは
Microsoft Azure が提供する API サービスで、画像をアップロードすることで画像内にあるテキストを検出して JSON データとして返してくれる OCR サービスです。
手書き文字の検出は英語のみとなります。
テキスト検出にはすでにレーニング済みの機械学習モデルが使用されるため、学習モデルを独自にカスタムして構築したい場合は、Custom Vision というサービスを利用してください。
Microsoft Azure
│
└ Azure Cognitive Services
│
├ Custom Vision(カスタム学習モデル)
│
└ Computer Vision(学習済モデル)
│
├ テキスト抽出(OCR API, Read API)
├ 画像解釈
├ 空間分析
・
・
・
Computer Vision ではテキスト検出の他にも、画像分析によって様々なオブジェクトの検出ができます。
無料枠の使用量上限
12 ヵ月の間(12 ヵ月分?)は、毎月 5,000 トランザクション( ≒ API 呼び出し回数)までは無料になります。
12 ヵ月を過ぎると、毎月 1,000 トランザクションごとに 112 円かかります。
100 万トランザクション以上になるとさらに安くなります。
通常は1秒間に 10 回まで、無料枠では1分間に 20 回まで呼び出しが可能です。
※金額は変更になる場合がありますので、必ず Azure のサイトにてご確認ください。
Computer Vision の設定
Computer Vision を利用するには、Microsoft Azure のアカウントとリソースの作成が必要です。
まずは Microsoft Azure アカウントを作成後、Azure portal にログインします。
Azure portal
https://portal.azure.com/
以降の手順はここでも解説いたしますが、詳細は公式の解説の方をご確認ください。
参考: クイックスタート: Read クライアント ライブラリまたは REST API を使用する- 前提条件
リソースを作成する
リソースとは、Microsoft Azure が提供するサービスの実体で、ここに利用するサービスを選択するとともに、リソースグループやサブスクリプションとの紐づけを行うことができます。
ざっくり言うと、リソースグループで利用者権限の設定、サブスクリプションで支払い情報の設定ができます。
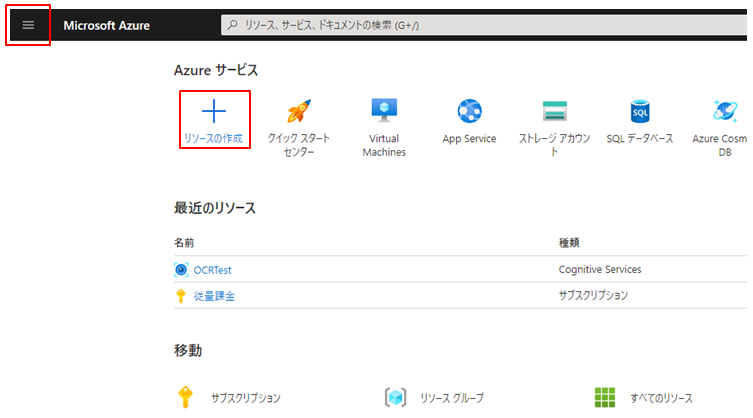
Azure portal にログイン後、画面上部にある「リソースの作成」ボタンもしくはバーガーメニューから「リソースの作成」を選択します。

検索フォームに computer vision と入力し、出てきた候補をクリックします。

「作成」ボタンをクリックします。

必須項目(※)を入力し、最下部のチェックボックスにチェックを入れ、「確認および作成」をクリックします。
価格レベルで Free を選択できる方は、Free を選択しましょう。


検証に成功したら、「作成」をクリックします。
ちなみに先ほどの画面で入力した「インスタンスの名前」がカスタムドメイン名となり、エンドポイント(API の URL)の構成要素になるようです。

デプロイが完了したらリソースに移動します。

この時点で API 呼び出しに必要なキーとエンドポイントが作成されています。
「キーの表示」をクリックして、キーとエンドポイントをメモしておきましょう。

アクセス制限を設定する
API の呼び出しをサーバから行う場合は、IP アドレスによるアクセス制限を設定しておくと良いでしょう。
バーガーメニューから「すべてのリソース」を選択し、該当のリソースを選択します。

左メニューの「ネットワーク」を選択し、許可するアクセス元の「選択したネットワークとプライベートエンドポイント」をチェックします。
下段、ファイアウォールにアクセスを許可するための IP 範囲を追加し、上段の「Save」をクリックして設定を保存します。

カスタムドメイン名が必要の旨のメッセージが出る場合は、「カスタムドメイン名を生成します」をクリックしてカスタムドメインを生成します。

これでようやく API を利用できるようになりました。
OCR API と Read API(読み取り API)
Computer Vision には2種類の OCR 用 API が存在します。
・OCR API
画像内の少量のテキストを素早く抽出するように設計されています。
同期型で API を呼び出すと即時に結果を返します。
・Read API
最新の認識モデルを使用し、大量のテキストを含む画像や、かなりの視覚ノイズがある画像に最適化されています。
非同期型で、API を呼び出すと応答として操作 ID が返されるので、この操作 ID を元に、結果取得用の API を呼び出して結果を取得します。
画像解析中の場合、結果取得用の API はstatus: runningを返すので、status: succeededになるまでリトライします。status: succeededになると解析結果がレスポンスボディに含まれます。
参考: Azure で OCR の使用を開始する
リクエストの形式(OCR API)
指定の URL にパラメータを付けて POST します。
API キーは HTTP ヘッダに設定します。
●HTTP メソッドと URL
POST https://{カスタムドメイン名}.cognitiveservices.azure.com/vision/v3.2/ocr?language=ja&detectOrientation=true&model-version=latest
●URL パラメータの説明
language(省略可)
画像内で検出されるテキストの言語コード。
デフォルトはunk(unknown)です。
detectOrientation(省略可)
画像内のテキストの向きを検出するかどうか。trueであれば画像の向きを検出し、さらに画像解析処理の前に修正しようとします。
デフォルトはfalseです。
model-version(省略可)
OCR モデルのバージョン。latest、latest-preview、2021-04-12が指定できます。
デフォルトはlatestです。
●HTTP ヘッダ
Ocp-Apim-Subscription-Key
API キーを指定します。
Content-Type
テキスト検出する画像の指定方法により異なります。
・application/json
画像ファイルにアクセスできる公開された URL を指定する場合。
・application/octet-stream
画像ファイルのバイナリデータを直接指定する場合。
・multipart/form-data
画像ファイルのバイナリデータをマルチパートフォーム形式で指定する場合。
●リクエストボディ
リクエストボディにはテキスト検出する画像の情報を指定します。
・画像ファイルの URL を指定する場合Content-Typeをapplication/jsonにし、以下のように JSON 形式で URL を設定します。
{
"url": "http://example.com/images/test.jpg"
}・画像ファイルのバイナリデータを指定する場合application/octet-stream、もしくはmultipart/form-dataの形式でバイナリーデータを設定します。
参考: Computer Vision API (v3.2) - OCR
レスポンスの形式(OCR API)
レスポンスデータの形式は以下のようになります。
{
"language": "ja",
"textAngle": -2.0000000000000338,
"orientation": "Up",
"regions":[]
}・language
検出されたテキストの言語コードが設定されます。
リクエストパラメタで指定されていなければ自動で検出されます。
・textAngle
テキストの向きを角度(ラジアン単位)で表します。
入力画像をこの角度だけ時計回りに回転させると、認識されるテキスト行が水平または垂直になります。
角度が検出できない場合はこのプロパティは存在しません。
・orientationtextAngleにしたがって画像を回転させた後に、テキストの上部が向いている方向を示します。Up, Down, Left, Right, NotDetectedの5種類があります。Upは正常な状態、Downは上下逆さまの状態、Leftは左向き、Rightは右向きの状態を表します。
リクエストパラメタでdetectOrientationが指定されなかった場合、もしくはテキストが検出されなかった場合はNotDetectedになります。
・regions
ここに検出されたテキストの結果が設定されます。
検出されたテキストの結果は、
区域 → 行 → 単語
のような階層構造で返されます。
それぞれの階層でboundingBoxにて左上の座標(単位:ピクセル)と幅・高さを取得できます。
"regions": [{
"boundingBox": "462,379,47,25",
"lines": [{
"boundingBox": "462,379,47,25",
"words": [{
"boundingBox": "462,379,47,25",
"text": "A"
},
{/* word */}, {/* word */}・・・]
},
{/* line */}, {/* line */}・・・]
},
{/* region */}, {/* region */}・・・]・区域【regions】
テキストの集まりを矩形に区切った領域を表します。
この区域に含まれる行情報、およびこの区域の左上右下の座標が入ります。
・行【lines】
複数の単語の集まりを改行で区切った領域を表します。
この行に含まれる単語情報、およびこの行の左上右下の座標が入ります。
・単語【words】
1つの単語です。
この単語のテキストデータと左上の座標 X, Y, 幅, 高さが入ります。
参考: Computer Vision API (v3.2) - OCR
リクエストの形式(Read API)
指定の URL にパラメータを付けて POST します。
API キーは HTTP ヘッダに設定します。
●HTTP メソッドと URL
POST https://{カスタムドメイン名}.cognitiveservices.azure.com/vision/v3.2/read/analyze?language=ja&model-version=latest
●URL パラメメータの説明
language(省略可)
画像内で検出されるテキストの言語コード。
デフォルトはunk(unknown)です。
pages(省略可)
PDF や TIFF ファイルにのみ利用されます。
readingOrder(省略可)
テキスト行が出力される順序を指定します。basicもしくはnaturalが指定できますが、naturalは恐らく日本語には対応できていません。
デフォルトはbasicです。
model-version(省略可)
OCR モデルのバージョン。latest、latest-preview、2021-04-12が指定できます。
デフォルトはlatestです。
●HTTP ヘッダ
OCR API と同じですが、Content-Typeのmultipart/form-dataには対応していないようです。
●リクエストボディ
OCR API と同じですが、Content-Typeのmultipart/form-dataには対応していないようです。
●レスポンス
この API はテキスト検出の依頼を受け付けた後すぐに復帰し、結果取得用の URL を返します。
結果取得用の URL は以下のレスポンスヘッダに設定されます。
レスポンスデータ本体はありません。
Operation-Location
テキスト検出の結果を取得する API の URL。
参考: Computer Vision API (v3.2) - Read
テキスト検出の結果取得(Read API)
テキスト検出の結果を取得するためには、上述の Read API から取得した結果取得用の API を呼び出します。
●HTTP メソッドと URL
GET https://{カスタムドメイン名}.api.cognitive.microsoft.com/vision/v3.2/read/analyzeResults/{操作ID}
※ Read API のレスポンスヘッダOperation-Locationに設定されている URL そのままで良いです。
●レスポンス
JSON 形式で結果が返ってきますが、呼び出しのタイミングによっては解析処理が未完である場合があります。
{
"status": "running"
}解析処理中の場合、結果取得用の API はstatus: runningを返すので、status: succeededになるまでリトライします。status: succeededになると解析結果がレスポンスボディ(analyzeResult)に含まれます。
{
"status": "succeeded",
"createdDateTime": "2020-09-21T15:27:53Z",
"lastUpdatedDateTime": "2020-09-21T15:27:55Z",
"analyzeResult": {
/* 解析結果 */
}
}●フィールド値の説明
status
画像解析処理の動作状態です。succeededの場合、analyzeResultに解析結果が含まれます。
・notStarted: 画像解析処理は開始されていません。
・running: 画像解析処理中です。
・failed: 画像解析処理は失敗しました。
・succeeded: 画像解析処理は成功しました。
createdDateTime
画像解析処理が依頼された日時(UTC)。
lastUpdatedDateTimestatusが最後に更新された日時(UTC)。
参考: Computer Vision API (v3.2) - Read
レスポンスの形式(Read API)
レスポンスデータは、上述のanalyzeResultに設定されます。
{
"status": "succeeded",
"createdDateTime": "2020-09-21T15:27:53Z",
"lastUpdatedDateTime": "2020-09-21T15:27:55Z",
"analyzeResult": {
"version": "3.1.0",
"modelVersion": "2021-04-12",
"readResults": [{/* 解析結果 */}, {/* 解析結果 */}, ・・・]
}
}いくつかのメタ情報とテキスト検出の結果がreadResultsに設定されます。
ここに検出されたテキストの結果が設定されます。
検出されたテキストの結果は、
ページ → 行 → 単語
のような階層構造で返されます。
「ページ」ではwidthとheight(単位:ピクセル)が取得でき、その他の階層ではそれぞれでboundingBoxにて四隅の座標(単位:ピクセル)を取得できます。
四隅の座標は、左上、右上、右下、左下の順番で格納されます。
"readResults": [{
"page": 1,
"angle": 12.8345,
"width": 1254,
"height": 704,
"unit": "pixel",
"lines": [{
"boundingBox": [145,0,1236,215,1225,272,134,55],
"text": "Nutrition Facts Amount Per Serving",
"appearance": {
"style": "print",
"styleConfidence": 1.0
},
"words": [{
"boundingBox": [144,0,460,57,450,112,135,57],
"text": "Nutrition",
"confidence": 0.981
},
{/* word */}, {/* word */}・・・]
},
{/* line */}, {/* line */}・・・]
},{
"page": 2,
・
・
}]
・ページ【page】
おおよそ画像全体を表します。
画像解析ではページが複数になることは恐らくないかと思います。
このページに含まれる行情報、およびこのページの縦横幅やその他のメタ情報(テキストの方向など)が入ります。
・行【lines】
複数の単語の集まりを改行で区切った領域を表します。
この行に含まれる単語情報、およびこの行のテキストと四隅の座標が入ります。
・単語【words】
1つの単語です。
この単語のテキストデータと四隅の座標が入ります。
●フィールド値の説明
analyzeResult.version
この結果に使用されるスキーマのバージョン。
analyzeResult.modelVersion
OCR モデルのバージョン。
リクエストパラメータmodel-versionで指定されている場合は同じ値が入ります。
analyzeResult.readResults.page
入力ドキュメントの1から始まるページ番号。
画像だと1のみ。
analyzeResult.readResults.angle
(-180, 180] の間の度で測定された、時計回り方向のテキストの方向。
analyzeResult.readResults.width、analyzeResult.readResults.height
画像の幅と高さ(ピクセル)。
analyzeResult.readResults.unitwidth、height、boundingBoxプロパティで使用される単位。
画像の場合は「ピクセル」、PDF の場合は「インチ」です。
analyzeResult.readResults.lines
テキスト行のリスト。
返される最大行数は1ページあたり 300 行です。
上から下、左から右にソートされますが、場合によっては近接がより優先的に扱われます。
analyzeResult.readResults.lines.boundingBox
矩形領域の四隅の座標。
左上、右上、右下、左下の順番です。
analyzeResult.readResults.lines.text
画像解析により検出された行のテキストコンテンツ。
analyzeResult.readResults.lines.appearance
行のスタイルと定性的な信頼スコア(0~1)。
analyzeResult.readResults.words
テキスト行の単語のリスト。
analyzeResult.readResults.words.boundingBox
テキスト行の単語のリスト。
analyzeResult.readResults.words.text
単語のテキストコンテンツ。
analyzeResult.readResults.words.confidence
単語行の定性的な信頼スコア(0~1)。

コメント